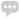|
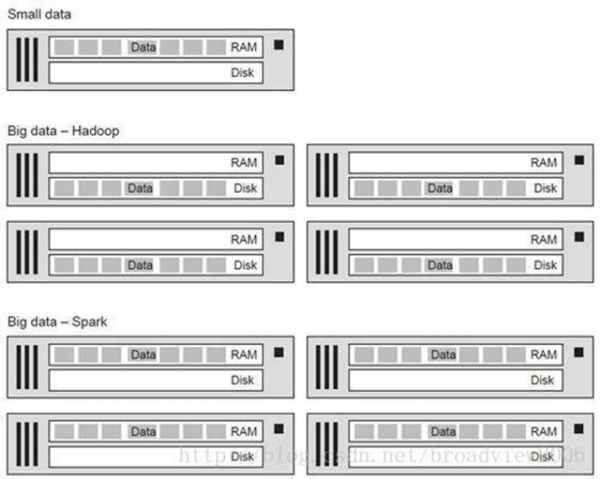
和 Hadoop 一样,Spark 提供了一个 Map/Reduce API(漫衍式计较)和漫衍式存储。二者主要的差异点是,Spark 在集群的内存中生存数据,而 Hadoop 在集群的磁盘中存储数据。
大数据对一些数据科学团队来说是 主要的挑战,因为在要求的可扩展性方面单机没有本领和容量来运行大局限数据处 理。另外,纵然专为大数据设计的系统,如 Hadoop,由于一些数据的属性问题也很难有效地处理惩罚图数据,我们将在本章的其他部门看到这方面的内容。 Apache Spark 与 Hadoop 雷同,数据漫衍式存储在处事器的集群可能是“节点”上。 差异的是,Spark 将数据生存在内存(RAM)中,Hadoop 把数据生存在磁盘(机器 硬盘可能 SSD 固态硬盘)中。 界说 :在图和集群计较方面,“节点”这个词有两种截然差异的意思。 图数据由极点和边构成,在这里“节点”与极点的意思临近。在集群计较 方面,构成集群的物理呆板也被称为“节点”。为制止夹杂,我们称图的 节点为极点,这也是 Spark 中的专有名词。而本书中的“节点”这个词我 们严格界说为集群中的单个物理计较节点。
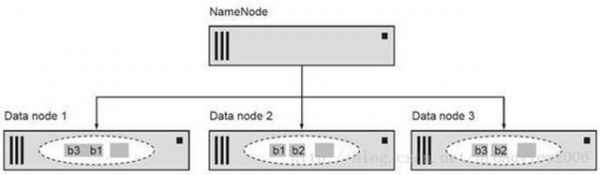
大数据因为数据量大单机无法处理惩罚。Hadoop 和 Spark 都是把数据漫衍在集群节点上的分 布式框架中。Spark 把漫衍式数据集存放在内存中,所以比 Hadoop 把数据存放在磁盘中 处理惩罚速度要快许多。 除了将要计较的数据生存的位置差异(内存和磁盘),Spark 的 API 比 Hadoop的 Map/Reduce API 更容易利用。Spark 利用简捷且表达力较好的 Scala 作为原生编程语言,写 Hadoop Map/Reduce 的 Java 代码行数与写 Spark 的 Scala 的代码行的数 量比一般是 10:1。 固然本书主要利用 Scala,可是你对 Scala 不熟悉也不消担忧,我们在第 3 章提 供了快速入门,包罗独特、艰涩和简洁的 Scala 语法。进一步熟悉 Java、C++、C#、 Python 等至少一门编程语言是须要的。 恍惚的大数据界说 此刻的“大数据”观念已经被很洪流平地夸大了。大数据的观念可以追溯到Google 在 2003 年颁发的 Google 文件系统的论文和 2004 年颁发的 Map/Reduce 论文。 大数据这个术语有多种差异的界说,而且有些界说已经失去了大数据所应有的意 义。可是简朴的焦点且至关重要的意义是:大数据是因数据自己太大,单机无法处理惩罚。 数据量已经呈爆炸性增长。数据来自网站的点击、处事器日志和带有传感器的 硬件等,这些称为数据源。有些数据是图数据(graph data),意味着由边和极点构成, 如一些协作类网站(属于“Web 2.0”的社交媒体的一种)。大的图数据集实际上是 众包的,譬喻常识相互毗连的 Wikipedia、Facebook 的伴侣数据、LinkedIn 的毗连数 据,可能 Twitter 的粉丝数据。 Hadoop :Spark 之前的世界 在接头 Spark 之前,我们总结一下 Hadoop 是如何办理大数据问题的,因为Spark 是成立在下面将要描写的焦点 Hadoop 观念之上的。 Hadoop 提供了在集群呆板中实现容错、并行处理惩罚的框架。Hadoop 有两个要害 本领 : HDFS—漫衍式存储 MapReduce—漫衍式计较 HDFS 提供了漫衍式、容错存储。NameNode 把单个大文件支解成小块,典范 的块巨细是 64MB 或 128MB。这些小块文件被分手在集群中的差异呆板上。容错性 是将每个文件的小块复制到必然数量的呆板节点上(默认复制到 3 个差异节点, 下图中为了暗示利便,将复制数配置为 2)。如果一个呆板节点失效,致使这个呆板上的 所有文件块不行用,但其他呆板节点可以提供缺失的文件块。这是 Hadoop 架构的 要害理念 :呆板出妨碍是正常运作的一部门。
三个漫衍式数据块通过 Hadoop 漫衍式文件系统(HDFS)保持两个副本。 MapReduce 是提供并行和漫衍式计较的 Hadoop 并行处理惩罚框架,如下图 。
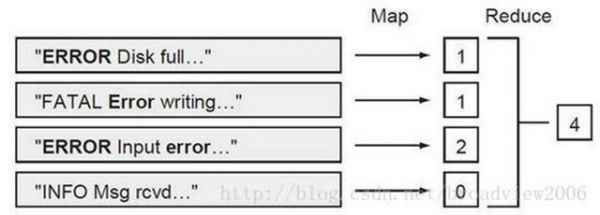
MapReduce 是被 Hadoop 和 Spark 都用到的一个数据处理惩罚范式。图中暗示计较处事器日 志文件中“error”呈现的次数,这是一个 MapReduce 操纵。凡是 Map 操纵是一对一的 操纵,对每一个源数据项生成一个相应的数据转换操纵。Reduce 是多对一的操纵,聚合 Map 阶段的输出。Hadoop 和 Spark 都用到了 MapReduce 范式。 用 MapReduce 框架,措施员写一个封装有 map 和 reduce 函数的独立代码片断来处 理 HDFS 上的数据集。为取到数据位置,代码打包(jar 名目)分发到数据节点, Map 操纵就在这些数据节点上执行,这制止了集群的数据传输导致耗损网络带宽。 对付 Reduce 聚合操纵,Map 的功效被传输到多个 Reduce 节点上做 reduce 操纵(称 之为 shuffling)。首先,Map 阶段是并行操纵的,Hadoop 提供了一个弹性机制,当 一个呆板节点可能一个处理惩罚进程失败时,计较会在其他呆板节点上重启。 |