|
前不久,Intel发布了网格互连(Mesh Interconnect)总线,晋升多核CPU的效率和机能表示,代替QPI和环形总线。 相似的,AMD在本年的EPYC霄龙处理惩罚器上也利用了Infinity Fabric互连架构。 之所以要进级互联(连)架构,其实就是向摩尔定律的再挑战。假如仅仅是用“胶水”的方法拼接焦点,带来的是大量的带宽和效率损失,并且芯片也会越来越大,甚至逾越制程工艺自己进步。
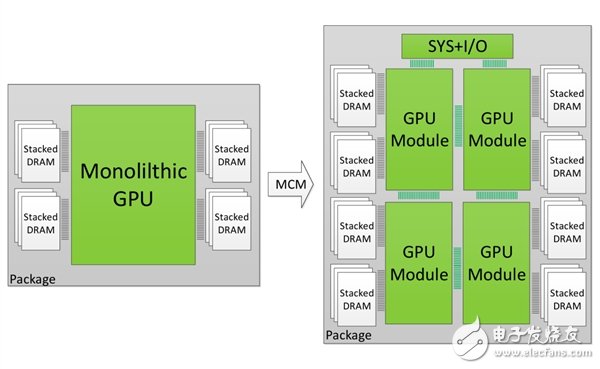
据外媒报道,NVIDIA研究人员克日展示了自家的MCM(多芯片封装)技能,用于将CPU/GPU/存储器/节制器等整合,最直观的浸染就是提高流处理惩罚器数、淘汰通讯层级和链路长度、缩小芯单方面积。
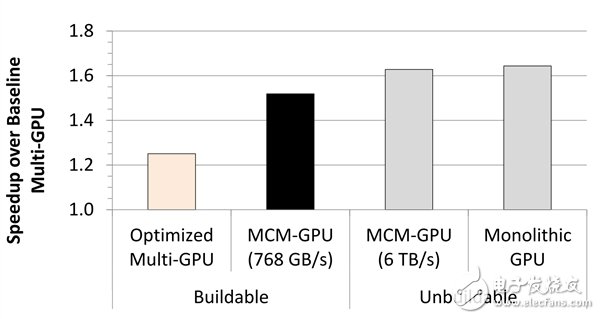
我们知道,本年基于Volta架构的Tesla V100是NV史上最大的焦点,面积到达815平方毫米,并且流处理惩罚器数只有5376(84组SM)。换言之,尽量换用了更先进的工艺,但Volta芯单方面积比上一代的GP100焦点(610平方毫米)还大。 新的MCM技能答允多个GPU模块与显存、节制器等在更小的面积内封装,凭据NV的纸面模仿,一组256SM的新技能显卡可以做到16384个流处理惩罚器,比用传统手段搭建的28组SM多芯显卡机能晋升45.5%,比同样流处理惩罚器数的多卡晋升26.8%。 凭据NV的设计思路,每个GPM(GPU模块)比今朝的大焦点都要小40%~60%之多,假如共同10nm/7nm工艺,可以在更小的体积中发挥更大的机能。
技能专区 谷歌宣布3款摄像应用 AI与摄影不分居 苹果Apple Watch 11月创新高,2018年总体出货量有望到达2500万 Pixel C平板进级Android 8.1后,数据自动擦除 谷歌发明iOS 11,iOS 11越狱信息或将果真 Windows再现高危裂痕,裂痕并未被果真,微软紧张修复 |